
it produces its own oxygen , duh
MinekPo1 [She/Her]
nya !!! :3333 gay uwu
I’m in a bad place rn so if I’m getting into an argument please tell me to disconnect for a bit as I dont deal with shit like that well :3
- 6 Posts
- 239 Comments
Joined 1 year ago
Cake day: June 14th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 2·3 months ago
2·3 months agoawawawawawawawawa ,
no , its made explicitly as an android application .

tubular , which is a fork of newpipe , works for me . AFAIK its maintained by the person who used to maintain newpipe+sponsorblock
it seems like it , but I have no idea !
edit : to clarify , I believe it does , using the CC1 & CC2 pins which are also used for other things , but I don’t know anything about USB protocol side , I should learn about it haha

more expensive imo.
actually the same pins (well one of them , though since the connector is rotationally symmetric you need two anyway) are used for USB Power Delivery and to negotiate what speed regime to operate in .
furthermore , USB On the go , which was introduced in USB 2.0 , offers the same functionality for USB Micro and USB Mini
actually they would be correct :
USB began as a protocol where one side (USB-A) takes the leading role and the other (USB-B) the following role . this was mandated by hardware with differently shaped plugs and ports . this made sense for the time as USB was ment to connect computers to peripherals .
however some devices don’t fit this binary that well : one might want to connect their phone to their computer to pull data off it , but they also might want to connect a keyboard to it , with the small form factor not allowing for both a USB-A and USB-B port. the solution was USB On-The-Go : USB Mini-A/B/AB and USB Micro-A/B/AB connectors have an additional pin which allows both modes of operations
with USB-C , aside from adding more pins and making the connector rotationally symmetric , a very similar yet differently named feature was included , since USB-C - USB-C connections were planed for
so yeah USB-A to USB-A connections are explicitly not allowed , for a similar reason as you only see CEE 7 (fine , or the objectively worse NEMA) plugs on both ends of a cable only in joke made cables . USB-C has additional hardware to support both sides using USB-C which USB-A , neither in the original or 3.0 revision , has .
sharing comment by @daigakunobaku273
Lterally citing Sergey Sumlenniy as “Eastern Europe expert”
LOL That’s basically all you need to know about the level of “expertise” that went into creating this video.
Since, for some reason, my comment is not yet deleted by the moderators, and somebody appears to have actually read it, I might as well point to the actual factual mistakes and problems with the video.
- These books are not, to the best of my knowledge (and I tried hard to find any evidence supporting the author’s claim) created, or approved, or distributed, or sponsored by any Russian state agency. They belong to a subgenre of male fantasy fulfillment books which target a specific audience of poorly educated lower middle to lower class males, typically 40+ years old, nostalgic of the Soviet Union (or, rather, of their rose-tinted pseudo-memory thereof).
There are thousands of other “military fiction” books targeting pretty much the same audience, but not having anything to do with “popadantsi”, including tons of S.T.A.L.K.E.R. fanfics (yes, S.T.A.L.K.E.R. fanfics sell as actual books in Russia, and in a typical book store you’ll find an entire section dedicated to them and to S.T.A.L.K.E.R. epigones, right next to the section dedicated to “popadantsi” literature, that is, if there even is such section. Most of the “popadantsi” books are actually self-published in electronic format, they are not nearly as popular as the author of the video portrays them to be. The other “military fiction” stuff sells much better).
You don’t need “government sponsorship hypothesis” in order to explain the existence of these books. They have their fanbase. That is not to say that the state propaganda has nothing to do with their popularity. The propaganda just exploits the same ressentiment and the same need to compensate for misfortune in one’s life by creating a fantasy world. People who enjoy these books are exactly the same people who sincerely believe the stuff translated by the Russian state TV. That does not mean the books are sponsored by the government.
- Outside of this relatively small, but substantial and loyal fanbase, the entirety of the Russian society laughs at these books, even the chauvinists and the Putin supporters. These books are a long-running meme in the Russian internet; the author didn’t even find or show the truly deranged and legendary stuff, like “The Popadanets Bee” (the actual title of an actual book; it tells the story of a Russian soldier, “heroically dying on Donbass in 2014”, whose mind is being transferred by the Higher Beings into the body of a bee living in the Emperor’s Garden of WWII Japan. The same book features Soviet pagan communist soldiers worshiping Svarog).
As was said before, most of these books don’t exist outside the Internet; the pool of their authors is relatively small and consists mostly of graphomaniacs, “publsihing” dozens of books each. The author, however, portrays them as a massive influence on the beliefs of Russians (They are not. The state media are. These books are a minor symptom.)
- Sergey Sumlenniy, whom the author unironically presents as an “Eastern Europe expert” (this phrase alone is a meme in the Russian opposition Twitter) is a Russian journalist and political “expert”, previously working for the Russian pro-Kremlin (and Kremlin-backed) magazine “Эксперт”. Later he worked as an expert that helped the Western companies working in Russia to evade the sanctions imposed on Russia after 2014 (I don’t want to go to jail for reminding you what happened this year).
At the time he gave interviews about his job to Russian federal media. This whole time, from 2014 to 2022, he mostly lived in Berlin off the money he earned by working for a pro-Kremlin magazine and by helping Western companies circumventing sanctions imposed on Russia. He never publically said as much as a word in protest to the Russian policies.
In February 2022 Sumlenniy has suddenly discovered that he is, in fact, a German, and that every single Russian, even the opposition leaders (especially the opposition leaders!) is guilty of Russia invading Ukraine (oh, sorry, I meant, protecting the people of Donbass and fighting nazism). Russians are “much more guilty than Germans in WWII” (direct quote), because any Russian who does not support the war could simply emigrate. The fact that they didn’t simply indicates, per Sumlenniy, that all Russians are brainwashed orcs, and opposition leaders are even worse than Putin, because Navalny is a neo-nazi and had slurred Ukraininans and Georgians, and everyone else is even uglier. But he, Sumlenniy, he is not responsible for the war. He is a German now, remember? (“We, germans” has also become a meme in the Russian emigrant Twitter.)

military grade autism
ew
 61·4 months ago
61·4 months agococaine shark , doo-doo , doo-doo , doo-doo cocaine shark , doo-doo , doo-doo , doo-doo cocaine shark , doo-doo , doo-doo , doo-doo cocaine shark !
oh gosh they are doing lobotomy again
yeah thats the point , the cybertruck design is retrofuturism

 8·5 months ago
8·5 months agofriendly interactive s hell
 1·5 months ago
1·5 months agobtw 90% of all pedo porn is done by the feds in order to poison the well
i’d say 99% -> https://wikispooks.com/wiki/Pedophocracy […]
that’s certainly a take , the linked wiki page contains no relevant information
 2·5 months ago
2·5 months agoAgh I made a mistake in my code:
if (recalc || numbers[i] != (hashstate[i] & 0xffffffff)) { hashstate[i] = hasher.hash(((uint64_t)p << 32) | numbers[i]); }Since I decided to pack the hashes and previous number values into a single array and then forgot to actually properly format the values, the hash counts generated by my code were nonsense. Not sure why I did that honestly.
Also, my data analysis was trash, since even with the correct data, which as you noted is in a lineal correlation with n!, my reasoning suggests that its growing faster than it is.
Here is a plot of the incorrect ratios compared to the correct ones, which is the proper analysis and also clearly shows something is wrong.
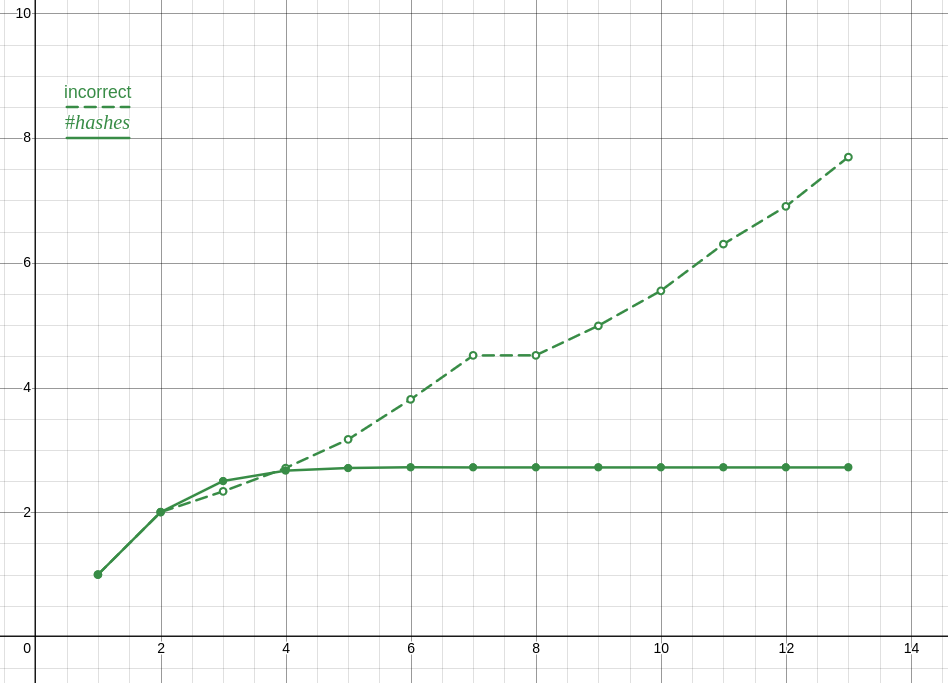
Anyway, and this is totally unrelated to me losing an internet argument and not coping well with that, I optimized my solution a lot and turns out its actually faster to only preform the check you are doing once or twice and narrow it down from there. The checks I’m doing are for the last two elements and the midpoint (though I tried moving that about with seemingly no effect ???) with the end check going to a branch without a loop. I’m not exactly sure why, despite the hour or two I spent profiling, though my guess is that it has something to do with caching?
Also FYI I compared performance with
-O3and after modifying your implementation to use sdbm and to actually use the previous hash instead of the previous value (plus misc changes, see patch).
you forgot about updating the hashes of items after items which were modified , so while it could be slightly faster than O((n!×n)²) , not by much as my data shows .
in other words , every time you update the first hash you also need to update all the hashes after it , etcetera
so the complexity is O(n×n + n×(n-1)×(n-1)+…+n!×1) , though I dont know how to simplify that
actually all of my effort was wasted since calculating the hamming distance between two lists of n hashes has a complexity of O(n) not O(1) agh
I realized this right after walking away from my devices from this to eat something :(
edit : you can calculate the hamming distance one element at a time just after rehashing that element so nevermind
honestly I was very suspicious that you could get away with only calling the hash function once per permutation , but I couldn’t think how to prove one way or another.
so I implemented it, first in python for prototyping then in c++ for longer runs… well only half of it, ie iterating over permutations and computing the hash, but not doing anything with it. unfortunately my implementation is O(n²) anyway, unsure if there is a way to optimize it, whatever. code
as of writing I have results for lists of n ∈ 1 … 13 (13 took 18 minutes, 12 took about 1 minute, cant be bothered to run it for longer) and the number of hashes does not follow n! as your reasoning suggests, but closer to n! ⋅ n.
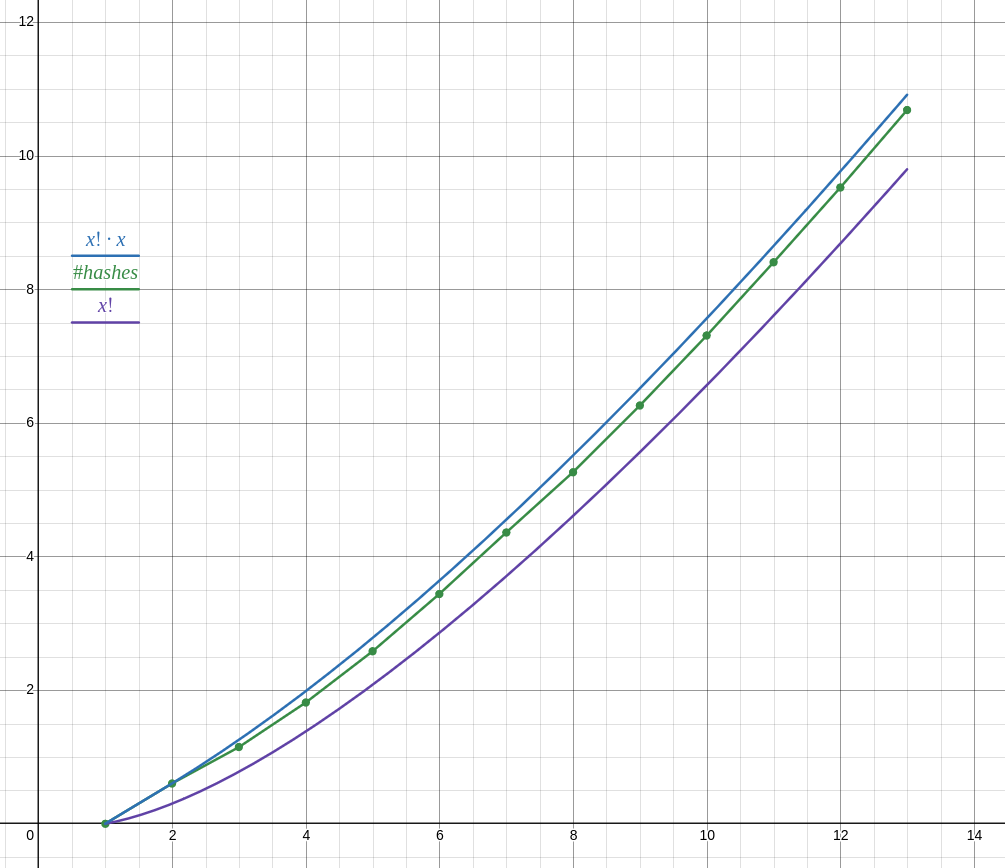
anyway with your proposed function it doesn’t seem to be possible to achieve O(n!²) complexity
also dont be so negative about your own creation. you could write an entire paper about this problem imho and have a problem with your name on it. though I would rather not have to title a paper “complexity of the magic lobster party problem” so yeah






{kind=link}
honestly while I agree that slightly longer keys wont be safe for long , but tbh I’m gonna sit a bit more on my 23-bit RSA keys before migrating