

If the files were already staged then git should have blobs in the git folder, so they should be recoverable.
I always found Git GUIs, especially the ones built into IDEs, to be more confusing and clunkier than working with Git on a terminal. It often feels like unlearning what one knows about Git, and relearning it the way that specific GUI demands.
Heck, I am going through the aforementioned feeling as I force myself to use Magit on Emacs. It just does not feel intuitive. But I will not give up until I have made an honest and full attempt.
The only sensible Git GUI I ever used is Sublime Merge[0], after a coworker praised it immensely. Even that is reserved for the rarest of the rare times when the changes in the workspace gets unwieldy and unruly. For every other instance: Git CLI on a terminal.
[0] https://www.sublimemerge.com/
E: typo, and link to mentioned GUI.
No backup, no sympathy.
5000 files
0 backups
Someone’s got their priorities mixed up.
having 5000 backups of 0 files is also kinda pointless.
You have to lose it all to know what matters (speaking from experience 😭)
Looks like windows should come with a dictionary.
“Huh, discard, I wonder what that does. Let’s try it on all my work from the last six months”
Idiots gonna idiot…
Problem is, there’s an entire generation of users that have gotten super used to “discard changes” as a means of signalling “on second thought, don’t do anything”.
Obligatory mention of file recovery as an option if you get in this situation.I recommend testdisk but there are other more gui friendly options.
NTFS takes a relatively long time to destroy the data so chances of recovery are good on Windows.
let’s turn this into a constructive angle for future devs and current juniors: just learn git cli, I promise you it is much simpler than it seems.
all those memes about git having like a thousand commands are true, but you really will only use like 7 at most per month.
learn push, pull, merge, squash, stash, reset, im probably missing like one or two
I promise you again: it is much simpler than it seems. and you won’t have to use these stupid git GUI things, and it will save you a hassle because you will know what commands you are running and what they do
short disclaimer: using git GUI is totally fine but low-key you are missing out on so much
You get pretty far with just clone, pull, add, commit, push
The main draw to the CLI for me is portability. I’ve been a dev for ten years now and used tons of different editors on different platforms and while each one had a different way to describe the changes, how to commit, or how to “sync” (shudder), the CLI hasn’t changed. I didn’t have to relearn a vital part of my workflow just because I wanted to try a different editor.
For a first step you can get away with just add, commit, push, and pull. Maybe reset, but tbh using git like svn at first is fine.
Next branch, checkout and merge. At this point show, log, bisect and blame also start to be useful.
I’m not a fan of stash, and would instead recommend reflog and cherry-pick as the first two advanced commands to learn. Then rebase and squash.
How about Git’s CLI stop being so shit? All of the options are obtuse & usually 3 ways to do the same thing.
Developers should normalize non-Git DVCSs.
im probably missing like one or two
commit. Lol
And mergetool ?
I don’t use push/pull btw.
Every time I mentor a dev on using git they insist so much on using some GUI. Even ones who are “proficient” take way longer to do any action than I can with cli. I had one dev who came from SVN land try and convince me that TortoiseGit was the only way to go
I died a little that day, and I never won her over to command line despite her coming to me kinda regularly to un-fuck her repository (still one of the best engineers I ever worked with and I honestly miss her… Just not her source control antics)
Currently using Tortoise and SVN for the first time at my job, and I hate it.
If I want to commit a selection of files, but not others, then I’m clicking boxes not typing filenames.
git add -p
The difference in speed is familiarity, not some inherent efficiency gain by typing commands into the cli.
So I’m normally a command line fan and have used git there. But I’m also using sublimerge and honestly I find it fantastic for untangling a bunch of changes that need to be in several commits; being able to quickly scroll through all the changed files, expand & collapse the diffs, select files, hunks, and lines directly in the gui for staging, etc. I can’t see that being any faster / easier on the command line.
Clone too 😁
Checkout
Personally, I’m pretty good with the CLI version, but sometimes I just use the Code VC interface. For some tasks (basic commit, pull, push) it’s pretty fast. I don’t know if it’s faster than CLI, but I switch between them depending on what I’m doing at that moment. Code has a built in console, so using either is pretty seemless and easy. If you only use the GUI you won’t ever understand it though. I think everyone should start with CLI.
Honestly, this is true for almost everything. GUIs obfiscate. They don’t help you learn, but try to take control away so you can’t mess up, and as an effect can’t do everything you may want.
I use gitkraken for two primary purposes:
-
Having a visual representation of my project history.
-
resolving merge conflicts
Of these, the first is really the only thing I really want a GUI for. I’ll just have it open on my side-screen if I’m managing some more or less messy branch structure or quickly want an overview of what has been done on which branches, where common ancestors are, etc. All the actual doing of things is done from the CLI, because it’s just better for that.
-
I fucking HATE when abstractions over git use cutesy names that git doesn’t use.
Honestly no idea why someone would go around a completely unknown menu in a new unknown editor and randomly click things with caution completely out the window. Not having a copy or trying a blank project, not even reading any messages. I mean even if we don’t know it’s a nuke button, God knows what other edits it could do to your code without you knowing.
This goes beyond rookie mistake. This is something 12 year old me would do. Same with the issue page being 90% swear words.
This is a disease of GUIs. Most people are so used to having their hands held and being unable to make a mistake that when a GUI actually gives you the power to fuck up they don’t expect it. I promise you, if this user was using the CLI, this wouldn’t have happened as easily.
I promise you, if this user
was using the CLIbacked up their files, this wouldn’t have happenedas easily.That too, but it seems like this was them attempting to back up their files. They just critically failed.
Using a program that’s not designed to be a backup solution that you are also unfamiliar with sounds even worse. Lol
I don’t even know why people ITT are blaming the IDE and completely ignoring this.
When you learn git, you do so on a dummy project, that has 5 files which are 10 characters long each.
An IDE is not made so you can’t break things, it is tool, and it should let you do things. It’s like complaining that Linux will let you delete your desktop environment. Some people actually want to delete your desktop environment. You can’t remove that option just because someone can accidentally do it by ignoring all the warnings.
Got will not delete untracked files though, which is what happened here. If you want to discard changes to a file with git, you first have to commit the file to the index at some point, which means there’s only ever so much damage an erroneous “git restore” or “git reset” can do. Specifically, neither of them will delete all the files in an existing project where VC has just been added.
This user was not using git though, he was using vs code. That button doesn’t say “git reset” it says “discard all changes”. And btw, what it does is “git clean”, which is something that git can do.
Just below the button there is a list of all the changes. In his case, there were 3000 changes of the type “file creation”. Discarding a file creation can only be made one way: deleting the file.
Anyway, this user is presumably in his learning phase, I would not assume that he knows what git reset or git restore actually do.
In other IDEs this discards tracked changes, untracked files usually stay untouched.
In my opinion, it’s a combination of user error and bad implementation here
Mein Gott!
They could have a warning though. I agree with you, but there are some easy ways to prevent this from happening. It just takes time to implement, and would be required in other places too. Is it worth the dev time? I doubt it.
There is a warning. IIRC it says “are you sure you want to discard all changes? This action is unreverisble”. In the context of version management. Creating a file is a change. And just below the button to discard all changes is the list of changes. In that list he could’ve seen 3000 changes of the type “file creation”, when you discard a file creation, it means to undo the creation, which is a deletion.
The button days what is going to do. There is a warning about what it’s going to do. And there is a list of the exact changes it’s going to undo.
The only way to avoid this from happening is to not have the button exist. In that case, the users that actually want to discard all changes would be unable to do so.
Linus Sebastian enters the chat
Honestly no idea why editors give shit random names instead of using the terms git uses.
I feel bad for this kid. That really is a bad warning dialog. Nowhere does it say it’s going to delete files. Anyone who thinks that’s good design needs a break.
Half the replies are basically “This should be obvious if your past five years of life experience is similar to mine, and if it isn’t then get fucked.” Just adding insult to injury.
Came here to say this. No one deserves this, not even new programmers who try to learn things.
Some programming tools are really powerful compared to what new users are used to. If you come from the world of Microsoft Office and Apple whatever it’s called, everything is saved automatically to cloud and there is some local backup file somewhere which you can just restore. Modern programs are designed to protect users against their own mistakes, and when suddenly that is taken away, it can be a jarring experience.
I’m not great at English, but “discard all changes” shouldn’t ever mean “Delete”.
the alternative to deleting is emptying the file contents, which is essentially the same…
I’m pretty sure vscode shows a confirmation dialog when discarding changes will permanently delete a file. I’ve done that recently with temporary files that were no longer needed.
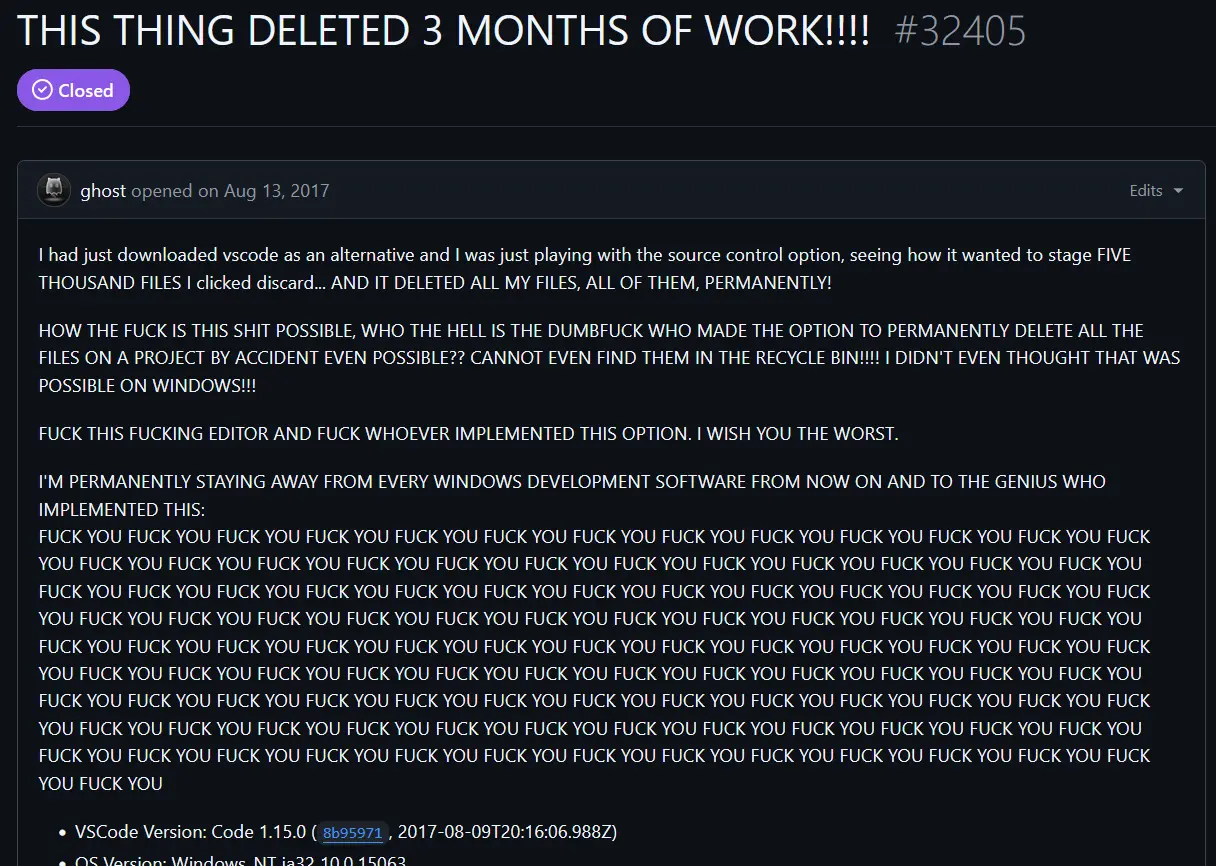
I remember following the drama back in the day. That warning you saw was the result of this now-classic bug report.
In the context of version control it does. Discarding a change that creates a file means deleting the file.
If you have set up your staging area for a commit you may want to discard (unstage) changes from the staging area, as opposed to discarding changes in the working directory.
Of course, the difference between the two is obvious if you’re using git CLI, but I can easily see someone using a GUI (and that maybe isn’t too familiar with git) misunderstanding “discard” as “unstage”.
Either way, what happened here indicates that all the files were somehow added to the VC, without having been committed first, or something like that, because git will not let you discard a file that is untracked, because that wouldn’t make any sense. The fact that the GUI let this person delete a bunch of files without first committing them to the index is what makes this a terrible design choice, and also what makes the use of the word “discard” misleading.
Ok fair enough, but I’m under the impression these files existed before the source control was implemented.
I guess it’s all up to how the program handles existing files.
I guess the newly created git repository was empty, and all the files that was present in the folder represented “changes”
Also, why not send them to the recycle bin? I never really thought about it before, but that does seem a reasonable UX improvement for this case
I wonder if there’s already a git extension to automatically stash the working tree on every clean/reset/checkout operation…
Because “the underlying Git nukes them right away, so why shouldn’t we perma-delete the files, too?”
Anything else’d be effort…
Honestly it probably just runs the underlying git command
Poor guy basically did a git reset —hard HEAD without even a git repository
Even reset hard wouldn’t delete untracked files. This was a complete overreach by the GUI, performing a
clean(and likely a forced one, as git’s requireForce defaults to true).And they did rectify that eventually, giving a warning, and an option to simply reset. It’s unfortunate this poor person had to be the trigger for that change.
If you ever happen to have 5000 uncommitted files, you shouldn’t be asking yourself if you should commit more often. You should be asking yourself how many new repos you should be making.
The person didn’t have any git repository; probably a new programmer that didn’t know how version control works and just clicked discard without understanding what that means in this situation.
Just curious, git doesn’t touch untracked files though?
git cleandoes. Turns out VSCode did a clean with that GUI option at that time, not sure of current behaviour.‘git reset’ won’t. ‘git clean’, on the other hand, most certainly does. Even then you have to --force it by default, to prevent an accidental clean.
Thanks, didn’t know!
This person is why we have that meme where devs would rather struggle for a week than spend a few hours reading the documentation.
This is without gitignore, so probably just installed one js dependency
Jesus saves, and so should you
Looks like someone forgot about the 3-2-1 rule. Teachable moment.
Go on…
https://www.backblaze.com/blog/the-3-2-1-backup-strategy/
This person lost 3 months of work because they couldn’t be assed to backup their data despite having three months to do so.
Never trust an OS, or a piece of software, to protect you. Protect yourself.
3 backups: 2 different places/media on-site 1 off-site
What about 2 offsite and 1 onsite? That’s been my approach, mostly due to storage limitations onsite.
technically isn’t a vcs supposed to be one of those different places?
Yes, but the OP went 3 months without it and then messed up during setup
The real issue is already going 3 months without source control.
The person didn’t have any git repository; probably a new programmer that didn’t know how version control works and just clicked discard without understanding what that means in this situation
I have heard things from another apprentice who just does not use version control at all and the only copies are on his laptop and on his desktop. He is also using node.js with only 1 class and doesn’t know about OOP (not sure if you even use that in js no clue 😅) and has one big file with 20k lines of code I have absolutely no clue how he navigates through it
Ey! Reminds me of my middle-school years! I still can’t belive I made an entire game without a single class… Just storing info in arrays and writing in comments what location represents what data. But I was a literal child, too young to read guides or sit through “long” tutorials.
I don’t want to sound too mean, but whenever I see anything similar at work, I wish that person get a job they’re actually good at. It’s fine and all that the company started hiring actual programmers to fix things, but the fact that the old crew still fucks shit up with senior privileges is a major grievance.
I know the type. Usually the kind of confident know-it-all who refuses to learn anything but delivers changes really quickly so management loves them. I had the misfortune to fix such a project after that ‘rock-star’ programmer left the company. Unfortunately the lack of professional standards in our industry allows people like that to continuously fail upwards. When I left the project they rehired them and let them design the v2 of the project we just fixed.
Jesus, reminds me of a similar story. My gf once lost a job to someone who literally just pasted code into LLMs, also delivering quickly, even tho it was hot garbage. Anyhow, she spent a lot of her time fixing his shit and so her output went down. I hope that company burns to the ground with completely un manageable software.
My company for the longest time had two engineers they would give all the new projects to. They would rush through some prototype code as fast as they could then management would bring in a new team to take the project over. The code was always garbage and crammed into one place. I kept getting new projects and instead of starting from a nice clean slate we always had to build on that garbage. It sucked so bad.
When I left the project they rehired them and let them design the v2 of the project we just fixed.
Lol. Wow.
And that is why I’ve been unable to work myself out of a job in all my long years as a developer.
Those are rookie numbers. I have at least a 35k one somewhere. More than one actually.
People run their businesses on this.
I once landed a job at a small company doing a software for medical analysis labs all over the country. Software had been around for over ten years at this point. They had no source control. Nothing. Absolute nightmare.
They were literally starting to use source control when I arrived.
In 2015.The “source control” when I first started was all the code on a shared drive, to check out a file you copied it to your machine, and renamed the extension on the shared drive to your initials.
When somebody edited without doing this there would be full blown meltdowns over lost work.
He just heard monoliths were in again
Reading this just give me a panic attack











{kind=link}